
Explore our resources
Browse the latest research, insights, and updates from the Reask team.
All resources
Insights
Research
News
Webinars
Brochures
Podcasts
Case studies

How hurricane risk models have evolved across three generations
Catastrophe modelling

European wildfire is no longer a peripheral peril. Is your view of risk keeping up?
European wildfire

5 parametric hurricane triggers, and where they quietly break
Parametric insurance

Improving ILS portfolio returns using seasonal climate forecasts
Climate view of risk

MS Amlin: What does a 2°C warmer climate mean for US hurricane losses?
Climate view of risk
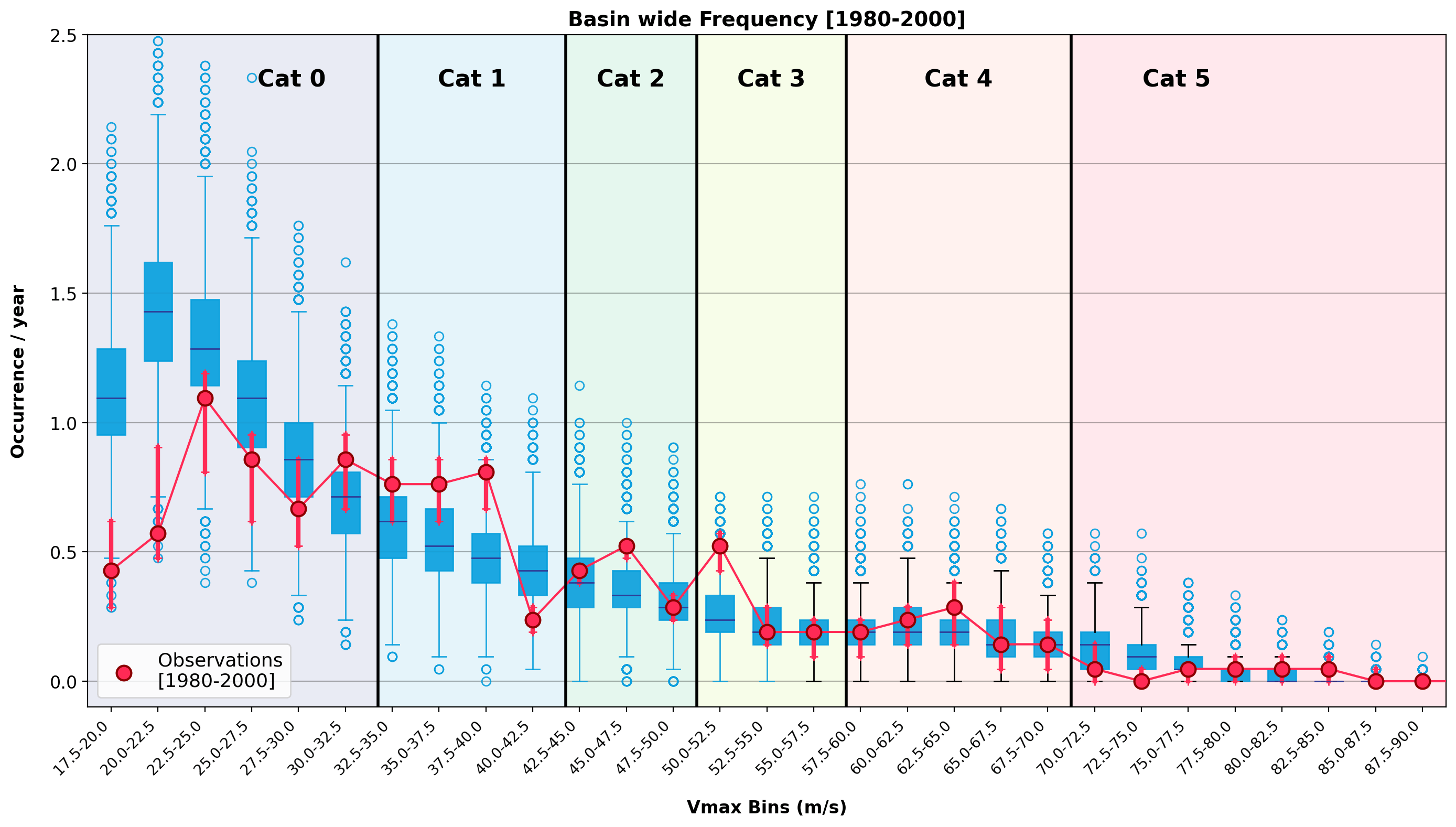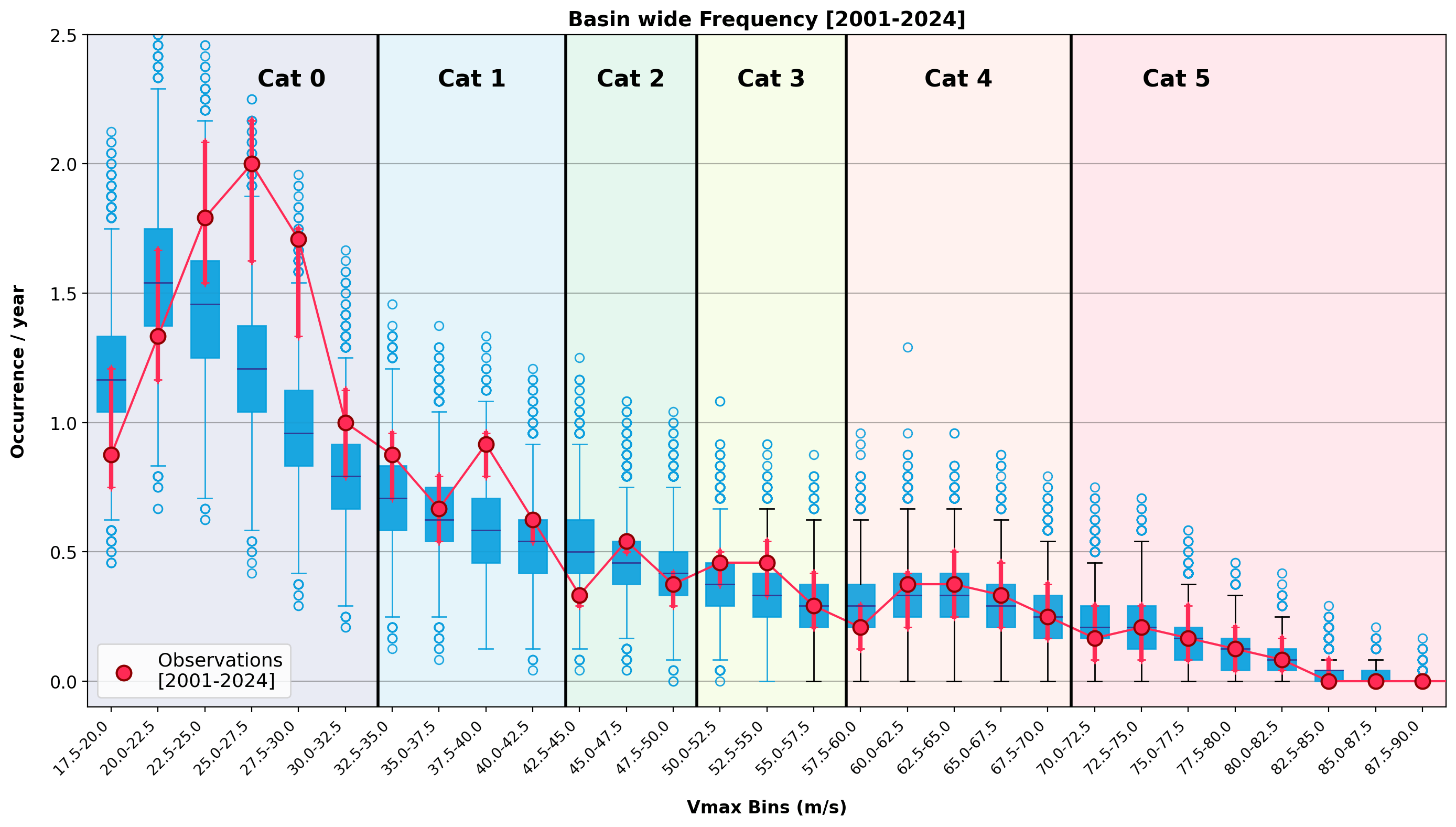
From plausible to useful: hurricane science and risk decision making
Climate view of risk
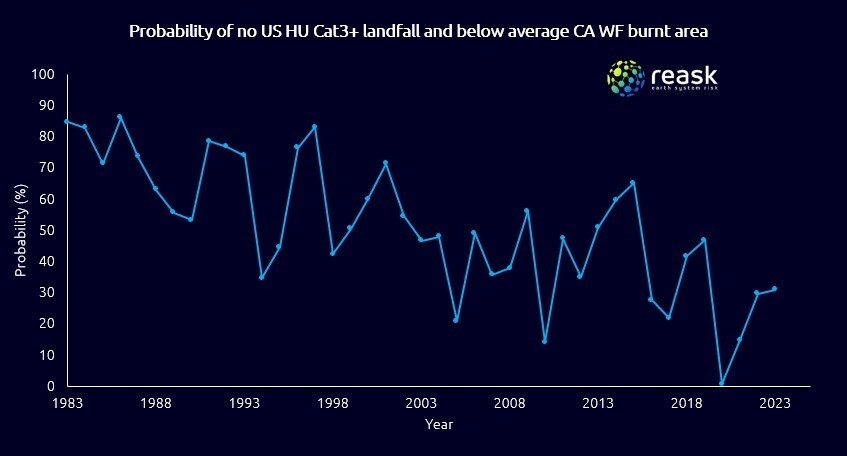
Was your 2025 success a low-probability outcome in a high-risk year?
Climate view of risk

How site-specific hazard data reduces premiums and basis risk in parametric insurance
Parametric insurance

Reask named catastrophe risk modelling solution of the year by InsuranceERM
Awards

Hurricane intensification: a changing reality
Climate view of risk

From hurricanes to major hurricanes: What 45 years of satellite data really tells us about a warming climate
Climate view of risk

Why a good trigger alone is not enough
Parametric insurance

Reask appoints Andy Rice as Chief Growth Officer to scale US expansion
Team

Hurricane Melissa and Jamaica: Understanding extreme event risk in a changing climate
Climate view of risk

From forecast to settlement: hurricane Melissa's 5-day timeline
Tropical cyclone modelling

Reask named Solutions Provider of the Year at the 2025 Parametric Insurer Awards
Awards

Climate slicing with Reask unified models
Climate view of risk

Reask partners with Howden Re to strengthen climate risk modelling in Europe
Partnership

Early loss estimation in the days leading up to a high-category hurricane landfall
Global early warnings

Predicting emergency call spikes during and after Hurricane Milton
Tropical cyclone modelling

Metryc: High-resolution tropical cyclone data for parametric insurance
Parametric insurance

Why observed hurricane landfall trends in the U.S. might not tell the whole story
Climate view of risk

A global stochastic drought model for (re)insurance
Drought modelling

Development of a climate-driven stochastic event catalogue for Wildfire in Europe
European wildfire

Reask TechTalk: The cost-benefits of global tropical cyclone early warning systems
Global early warnings

Reask secures investment from BlueOrchard’s InsuResilience private equity fund
Funding

Reask TechTalk: Parametric Insurance for Tropical Cyclones
Parametric insurance

Reask appoints Joss Matthewman as Chief Revenue Officer
Team

Revolutionising hurricane risk modelling – InsuranceERM & Reask webinar
Tropical cyclone modelling

Reask and AXA Climate announce partnership on parametric windstorm insurance
Partnership

Why your risk models may be underestimating extreme weather losses
Climate view of risk

Reask TechTalk: Using climate-connected hurricane event set for dynamic risk management
Climate view of risk

Reask joins forces with cat-modelling leaders in InsuranceERM special report
Catastrophe modelling

Revolutionising catastrophe modelling: InsuranceERM’s 2025 Special Report
Catastrophe modelling

Lessons learned from the 2024 hurricane season
LiveCyc

Expanding the power of extreme weather events and risk forecasting
Catastrophe modelling

Unveiling the cracks in the housing market
Drought modelling

GARP rethinking natural catastrophe modelling
Catastrophe modelling

Climate-connected catastrophe modelling for the reinsurance industry
Catastrophe modelling

Global drought risk model
Drought modelling

EGU 2024: Tropical cyclone induced coastal flooding under current and future climates
Flood modelling

A machine learning approach to model over-ocean tropical cyclone precipitation
Tropical cyclone modelling
Climate-connected catastrophe modelling for the insurance industry
Catastrophe modelling

A machine learning approach to modeling tropical cyclone wind field uncertainty
Wind modelling

Building transparent coverage for hurricane risks
Parametric insurance

Why process-based event simulations beat simpler risk models
Catastrophe modelling

Hurricane risk under a warming climate
Climate view of risk

Smart parametric insurance with Metryc
Parametric insurance

Reask announces $6.55 m total seed funding
Funding

Why “number of affected people” is a vague measure of disaster impact
Parametric insurance

Reask appoints David Schmid as Head of Parametric Products
Team

Reask appoints Louise Braybrooke as Chief Client Officer
Team

Reask appoints (re)insurance and capital markets specialist Jamie Rodney as CEO
Team

Turning catastrophe models into predictive tools
Climate view of risk

Reask raises seed funding to advance global nat-cat modelling
Funding

Introducing Metryc: Reask’s tropical cyclone calculation agent
Parametric insurance

Reask's Unified Tropical Cyclone model: a physics-based, climate-connected approach to global TC risk
Climate view of risk

Towards the next generation of cat models: why there is nothing special about history
Catastrophe modelling

How catastrophe models must change to incorporate climate variability
Catastrophe modelling

InCyc: A global tropical cyclone simulation database
Tropical cyclone modelling
All resources
Insights
Research
News
Webinars
Brochures
Podcasts
Case studies
How hurricane risk models have evolved across three generations
Catastrophe modelling
European wildfire is no longer a peripheral peril. Is your view of risk keeping up?
European wildfire
5 parametric hurricane triggers, and where they quietly break
Parametric insurance
Improving ILS portfolio returns using seasonal climate forecasts
Climate view of risk
MS Amlin: What does a 2°C warmer climate mean for US hurricane losses?
Climate view of risk
From plausible to useful: hurricane science and risk decision making
Climate view of risk
Was your 2025 success a low-probability outcome in a high-risk year?
Climate view of risk
How site-specific hazard data reduces premiums and basis risk in parametric insurance
Parametric insurance
Reask named catastrophe risk modelling solution of the year by InsuranceERM
Awards
Hurricane intensification: a changing reality
Climate view of risk
From hurricanes to major hurricanes: What 45 years of satellite data really tells us about a warming climate
Climate view of risk
Why a good trigger alone is not enough
Parametric insurance
Reask appoints Andy Rice as Chief Growth Officer to scale US expansion
Team
Hurricane Melissa and Jamaica: Understanding extreme event risk in a changing climate
Climate view of risk
From forecast to settlement: hurricane Melissa's 5-day timeline
Tropical cyclone modelling
Reask named Solutions Provider of the Year at the 2025 Parametric Insurer Awards
Awards
Climate slicing with Reask unified models
Climate view of risk
Reask partners with Howden Re to strengthen climate risk modelling in Europe
Partnership
Early loss estimation in the days leading up to a high-category hurricane landfall
Global early warnings
Predicting emergency call spikes during and after Hurricane Milton
Tropical cyclone modelling
Metryc: High-resolution tropical cyclone data for parametric insurance
Parametric insurance
Why observed hurricane landfall trends in the U.S. might not tell the whole story
Climate view of risk
A global stochastic drought model for (re)insurance
Drought modelling
Development of a climate-driven stochastic event catalogue for Wildfire in Europe
European wildfire
Reask TechTalk: The cost-benefits of global tropical cyclone early warning systems
Global early warnings
Reask secures investment from BlueOrchard’s InsuResilience private equity fund
Funding
Reask TechTalk: Parametric Insurance for Tropical Cyclones
Parametric insurance
Reask appoints Joss Matthewman as Chief Revenue Officer
Team
Revolutionising hurricane risk modelling – InsuranceERM & Reask webinar
Tropical cyclone modelling
Reask and AXA Climate announce partnership on parametric windstorm insurance
Partnership
Why your risk models may be underestimating extreme weather losses
Climate view of risk
Reask TechTalk: Using climate-connected hurricane event set for dynamic risk management
Climate view of risk
Reask joins forces with cat-modelling leaders in InsuranceERM special report
Catastrophe modelling
Revolutionising catastrophe modelling: InsuranceERM’s 2025 Special Report
Catastrophe modelling
Lessons learned from the 2024 hurricane season
LiveCyc
Expanding the power of extreme weather events and risk forecasting
Catastrophe modelling
Unveiling the cracks in the housing market
Drought modelling
GARP rethinking natural catastrophe modelling
Catastrophe modelling
Climate-connected catastrophe modelling for the reinsurance industry
Catastrophe modelling
Global drought risk model
Drought modelling
EGU 2024: Tropical cyclone induced coastal flooding under current and future climates
Flood modelling
A machine learning approach to model over-ocean tropical cyclone precipitation
Tropical cyclone modelling
Climate-connected catastrophe modelling for the insurance industry
Catastrophe modelling
A machine learning approach to modeling tropical cyclone wind field uncertainty
Wind modelling
Building transparent coverage for hurricane risks
Parametric insurance
Why process-based event simulations beat simpler risk models
Catastrophe modelling
Hurricane risk under a warming climate
Climate view of risk
Smart parametric insurance with Metryc
Parametric insurance
Reask announces $6.55 m total seed funding
Funding
Why “number of affected people” is a vague measure of disaster impact
Parametric insurance
Reask appoints David Schmid as Head of Parametric Products
Team
Reask appoints Louise Braybrooke as Chief Client Officer
Team
Reask appoints (re)insurance and capital markets specialist Jamie Rodney as CEO
Team
Turning catastrophe models into predictive tools
Climate view of risk
Reask raises seed funding to advance global nat-cat modelling
Funding
Introducing Metryc: Reask’s tropical cyclone calculation agent
Parametric insurance
Reask's Unified Tropical Cyclone model: a physics-based, climate-connected approach to global TC risk
Climate view of risk
Towards the next generation of cat models: why there is nothing special about history
Catastrophe modelling
How catastrophe models must change to incorporate climate variability
Catastrophe modelling
InCyc: A global tropical cyclone simulation database
Tropical cyclone modelling

Stay in the loop
Sign up for the Reask newsletter for the latest climate science, model updates, and industry insights *
* By subscribing, you agree to receive the Reask newsletter. You can unsubscribe at any time. For more details, see our Privacy Policy.
2026 © Reask
All rights reserved
Stay in the loop
Sign up for the Reask newsletter for the latest climate science, model updates, and industry insights *
* By subscribing, you agree to receive the Reask newsletter. You can unsubscribe at any time. For more details, see our Privacy Policy.
2026 © Reask
All rights reserved
Stay in the loop
Sign up for the Reask newsletter for the latest climate science, model updates, and industry insights *
* By subscribing, you agree to receive the Reask newsletter. You can unsubscribe at any time. For more details, see our Privacy Policy.
2026 © Reask
All rights reserved